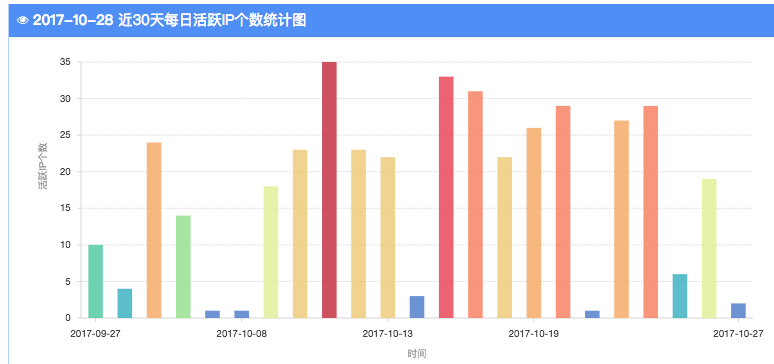
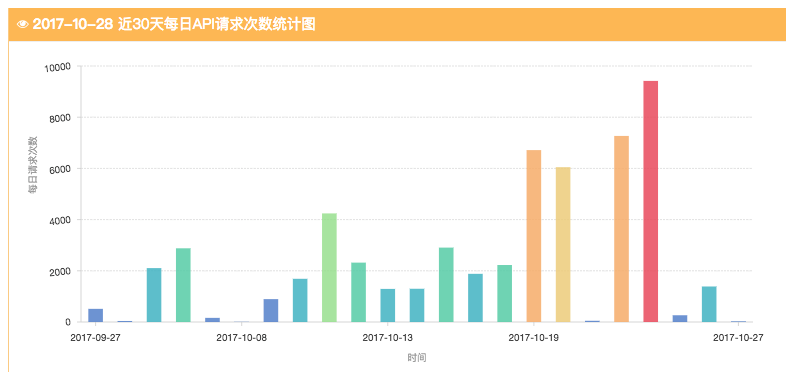
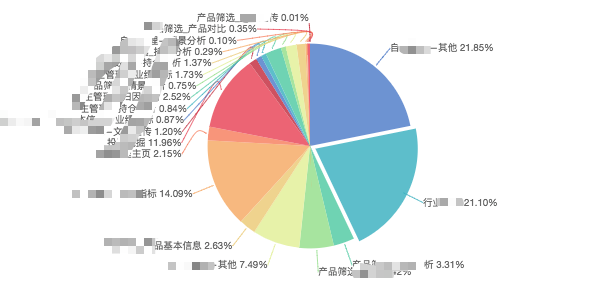
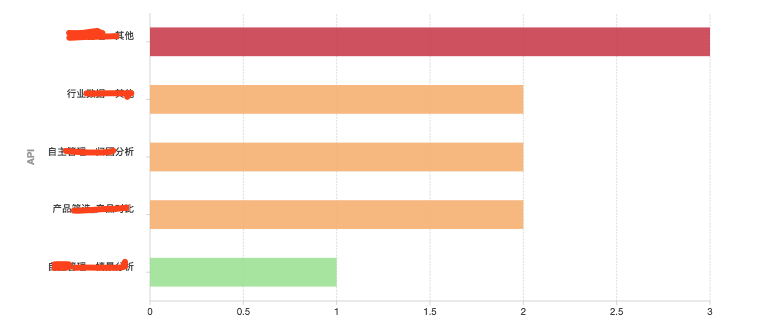
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| # -*- coding: utf-8 -*-
import re
import time
import os
import arrow
import pandas as pd
import json
import io_tosql
import shutil
from sqlalchemy import create_engine
engine_user_info = create_engine(
"mysql+pymysql://{}:{}@{}:{}/{}".format('usr', 'pwd', 'host','port', 'db'),
connect_args={"charset": "utf8"})
def parse(filename):
month_abr = {"Jan":"01", "Feb":"02", "Mar":"03", "Apr":"04", "May":"05", "Jun":"06",
"Jul":"07", "Aug":"08", "Sep":"09", "Oct":"10", "Nov":"11", "Dec":"12"}
dfs = []
try:
i = 0
file = open(filename)
for line in file:
pattern = "(\d+\.\d+\.\d+\.\d+).*?\[(.*?)\].*?(\w+) (/.*?) .*?\" (\d+) \[(.*?)\] (\d+) \"(.*?)\" \"(.*?)\" \"(.*?)\""
s = re.search(pattern, line)
if s:
remote_addr = s.group(1)
local_time = s.group(2)
request_method = s.group(3)
request_url = s.group(4)
status = s.group(5)
request_body = s.group(6)
body_bytes_sent = s.group(7)
http_referer = s.group(8)
http_user_agent = s.group(9)
http_x_forwarded_for = s.group(10)
# 30/Sep/2017:01:08:39 +0000
for mon in month_abr.keys():
if mon in local_time:
local_time = local_time.replace(mon, month_abr[mon])
break
lt = arrow.get(local_time, "DD/MM/YYYY:HH:mm:ss")
lt = lt.shift(hours=8)
local_time = str(lt.datetime)
i = i+1
# print("line:{} > {}".format(i, local_time))
if request_body != '-':
try:
request_body = request_body.replace(r'\x22', '"').replace("null", '""')
request_body_dict = json.loads(request_body)
fund_id = request_body_dict.get('fund_id', None)
user_id = request_body_dict.get('user_id', None)
if user_id is None:
user_id = request_body_dict.get('userId', None)
except Exception as e:
print("request_body:{}".format(request_body))
print(e)
fund_id = None
user_id = None
else:
fund_id = None
user_id = None
if request_method not in ("GET", "POST"):
# print(request_method)
continue
df = pd.DataFrame({"remote_addr": [remote_addr], "request_method": [request_method], "local_time": [local_time],
"request_url": [request_url], "status": [status], "request_body": [request_body],
"body_bytes_sent": [body_bytes_sent], "http_referer": [http_referer],
"http_user_agent": [http_user_agent], "http_x_forwarded_for": [http_x_forwarded_for],
"fund_id": [fund_id], "user_id": [user_id]
})
df['create_at'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))
# print(df)
dfs.append(df)
#每100条写数据库
if len(dfs) >= 100:
df_all = pd.concat(dfs)
df_all = df_all.drop_duplicates(subset=['remote_addr', 'request_url','local_time'])
df_all.to_sql("log_table", engine, if_exists="append", index=False)
print("写入长度为:" + str(len(df_all)))
dfs = []
df_all = pd.concat(dfs)
df_all = df_all.drop_duplicates(subset=['remote_addr', 'request_url','local_time'])
df_all.to_sql("log_table", engine, if_exists="append", index=False)
except Exception as e:
print(e)
|